Large Language Model Introspection
Tactics for interpreting LLM behavior by way of Anthropic's circuit-tracing research
This post is a high-level take and explainer on a recent Anthropic mechanistic interpretability paper on circuit-tracing [1]. Familiarity with neural networks and the transformer architecture is presumed in some sections.
Interpretability Value Proposition
Machine learning offers a toolkit for modeling latent patterns in data. The value of applying machine learning is generally proportional to the inscrutability of the pattern we desire to model. That is, the more readily a human can appreciate and codify relationships in data, the less useful it perhaps is to try and coerce a machine learning algorithm to do this work on our behalf. Conversely, the more opaque the relationship is, the stronger the case for an ML-driven approach becomes. Once a pattern is captured in a model, the process of extracting it can be automated. For example, automated inbox triage to label email as spam, promotional or high-priority.
Machine learning algorithms come in various flavors, some more inherently interpretable than others. As a trivial example, consider a linear regression model that fits a line to a two-dimensional dataset that captures historical sales of products by the number of TV advertisements placed.
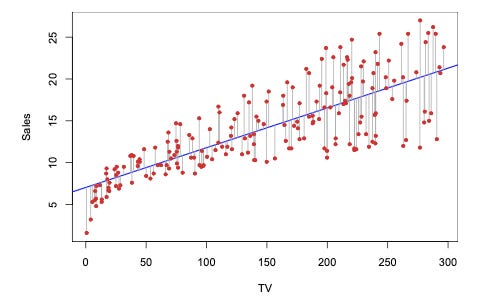
We could debate the precise nature of the relationship between advertisements and sales here, but the slope of the fit line is easy to interpret: the model suggests an increase of about one sale for every 15 advertisements. The inherent interpretability here allows us to question or affirm our suspicions about the underlying relationship and can drive follow-on analysis.
On the less interpretable end of this spectrum, we have the “deep” configuration of the neural network, which can encode arbitrarily complex functions and deep hierarchical relationships elicited from the training data. The deep learning approach often yields a model that is densely packed with relevant signals that are mixed and alternately amplified or suppressed across the network’s layers to achieve its prediction task.
Large language models (LLMs), the subject of the paper under consideration in this article, often consist of billions of weight and bias parameters. A fundamental challenge in the application of deep neural networks, both in LLMs, and neural networks more broadly, is an authentic interpretation of the relationships these parameters capture. Mechanistic interpretability, a sub-domain of machine learning interpretability, exists to meet this challenge. Neel Nanda, the lead of Google DeepMind's mechanistic interpretability team, describes the movement as "The field of study of reverse engineering neural networks from the learned weights down to human-interpretable algorithms" [9] It is in this context which we turn to Anthropic’s recent research.
Anthropic’s Circuit Tracing Effort
Anthropic is a leading provider of so-called frontier LLMs. The company has published a non-trivial body of research on LLM interpretability [10]. A consistent theme in their research has been understanding the end-to-end behavior of multi-neuron circuits (see Concepts, below). Circuit Tracing: Revealing Computational Graphs in Language Models [1] is a recent addition to the research, and outlines an evolution of mechanistic interpretability that illuminates the interplay of learned features which in turn reveal the nature and intuition behind these circuits.
This article first explains the rationale for the paper then introduces key concepts before discussing the nature of the Anthropic interventions. The article concludes with some analysis on where the paper leaves off.
Motivation
The rationale for the pursuit of interpretability laid out above holds in the context of large language models. Arriving at a correct and exhaustive explanation for a model’s behavior is the goal of mechanistic interpretability, and the Anthropic circuit-tracing research directly supports that ambition. However we first need to appreciate the scope of the problem that mechanistic interpretability is up against.
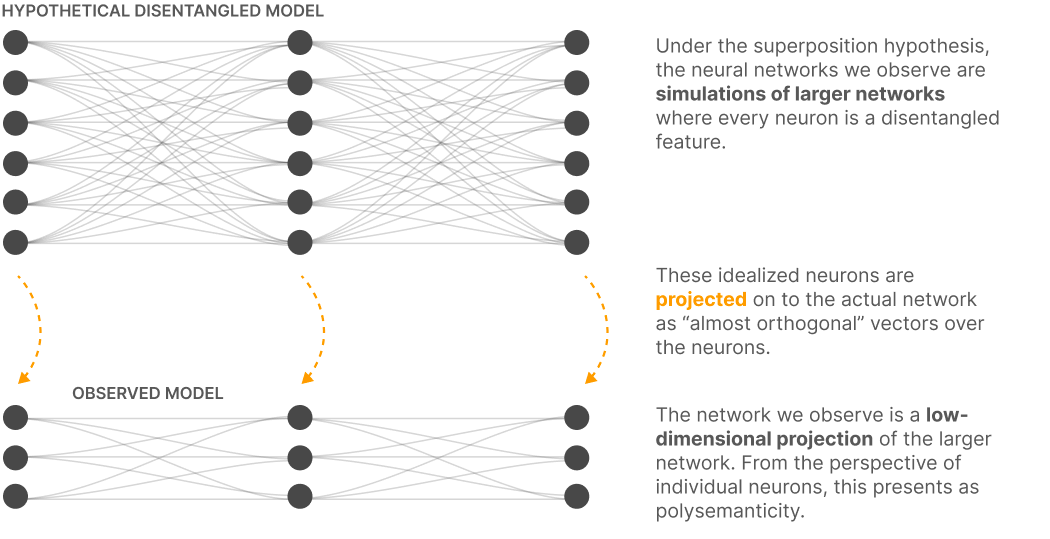
Superposition: Neural networks are often designed to capture and represent patterns in fewer dimensions than a full articulation of the underlying pattern would otherwise require. The compression of information that this demands can induce encoding of meaning in a context-dependent and overlapping manner (see polysemanticity). Disentangling the encoded concepts is often a prerequisite for tracing and interpreting model behavior.
Representation mismatch: Humans have evolved an intuition about many concepts that do not necessarily map smoothly onto the hierarchical knowledge that a model accumulates internally. Even when a sparse pathway captures just a single, discrete concept, these may be and often are foreign to us. Studying how distinct concepts interact and accumulate to achieve a function that manifests at the output layer requires a grouping and tracing mechanism.
Scale: Even small LLMs have parameters numbering in the millions. Dealing with manifold paths through the associated connections, and the ways in which these circuits evolve based on context, suggests a combinatorial explosion that we must seek to automate if we hope to achieve insight, let alone a global1 understanding.
These obstacles to understanding are what continue to motivate mechanistic interpretability research and are the context within which the Anthropic contributions on circuit tracing can be properly valued.
Key Concepts
The following concepts are foundational to absorbing the paper and are inventoried here to serve as a quick reference for the sections that follow. The frequent use of these terms in the paper and in related literature warrant the separate bookkeeping. See [9] for a thorough treatment of mechanistic interpretability concepts and a more authoritative definition of terms.
Mechanistic Faithfulness: A term that describes the degree to which any replacement components (e.g. transcoders) reproduce the original model’s output when swapped in. A high degree of faithfulness corresponds to a fair representation of the actual underlying mechanisms.
Polysemanticity: The tendency of a neural network to incorporate representations of multiple distinct concepts in a single neuron or collection of neurons. Often thought to be induced in neural networks by superposition.
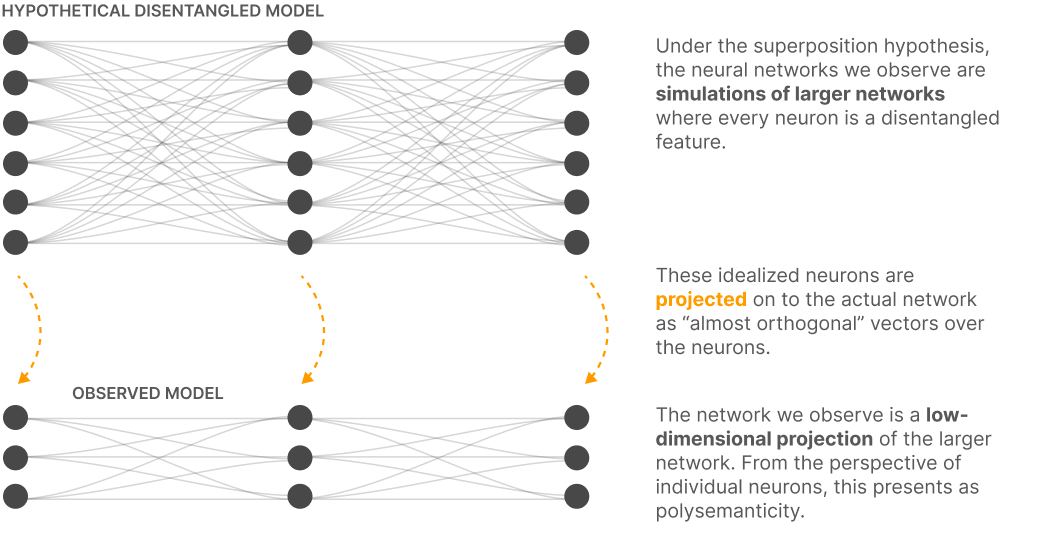
Figure 1. Schematic of notional dense model relationships as they pertain to a hypothetical disentangled, interpretable variant. This is one rationale for the phenomenon of polysemanticity. Reproduced under fair use for purposes of critical review. Source: Anthropic, “Towards Monosemanticity: Decomposing Language Models With Dictionary Learning” 2023 [7]. Monosemanticity: The representation of a single concept or feature by a single neuron.
Features: Groupings of artificial neurons that collaborate to create a high-level, interpretable behavior. Note feature boundaries are fuzzy, unlike their biological counterparts [2]. In a dense network, individual concepts are distributed across multiple neurons and their manifestation is context sensitive. In the sparse networks, features are pressured into being activated by a single neuron or small number of neurons.
Supernodes : Collections of features that are manually grouped to aid human understanding and decrease cognitive load when interpreting attribution graphs. More treatment here.
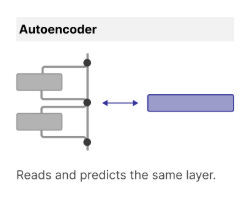
Sparse autoencoder (SAE): An autoencoder configured with a much larger hidden layer which is designed to learn a sparse representation of its dense and polysemantic input. Leverages regularization to coerce the network into learning fewer, more interpretable features, supporting with the monosemanticity aspiration.

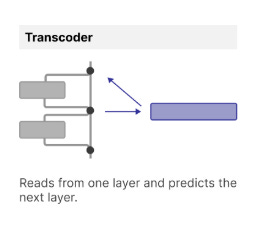
Autoencoder applied to the interpretability problem. Here the sparse model receives and emits the same information, reconstructing a more interpretable version in the process. [15] Transcoder: Variation on the SAE that learns a sparse representation of a given layer's function. These two auxiliary networks differ only in their training objective. The SAE is applied to explain a layer's output, whereas the transcoder bridges two layers and develops an approximation of the logic that layer carries. Critically the transcoder allows for interventions and tracing of features across a target model that the SAE cannot [8].
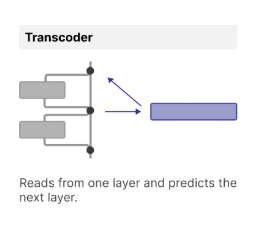
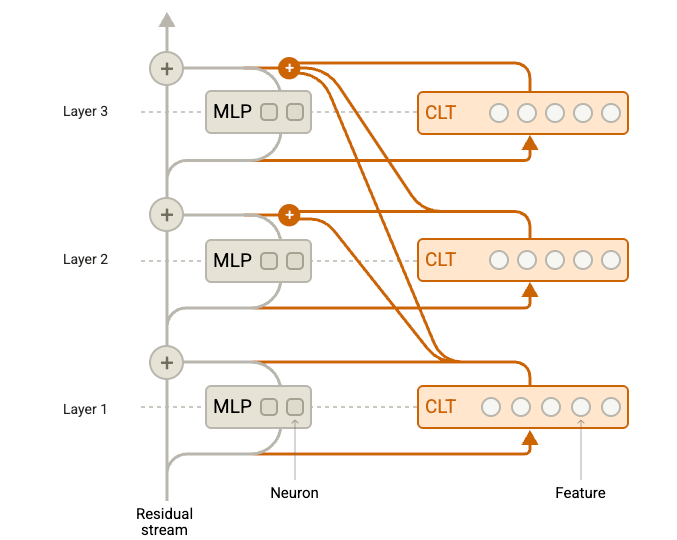
The transcoder sees the same inputs as the target layer in the network, and is trained to mimic that layer. The use of regularization and a larger encoding space leads to interpretability in the resulting weights. Source: [15]. Cross-layer transcoder (CLT) : A specific application of the transcoder paradigm in the Anthropic research where a given transcoder's output is furnished to all subsequent transcoder layers, enabling the tracing of circuits across (otherwise inscrutable) layers of the model. See this discussion on architecture for more detail.
Anatomy of the Intervention
Building on an immense body of prior work in the research space, the Anthropic team reports a more inspectable and faithful LLM circuit tracer. Their approach is characterized by the following:
Target model: The target of their explainability interventions is a "small” 18-layer model referred to as 18L and a variant of Anthropic’s Claude Haiku 3.5 model. [1]
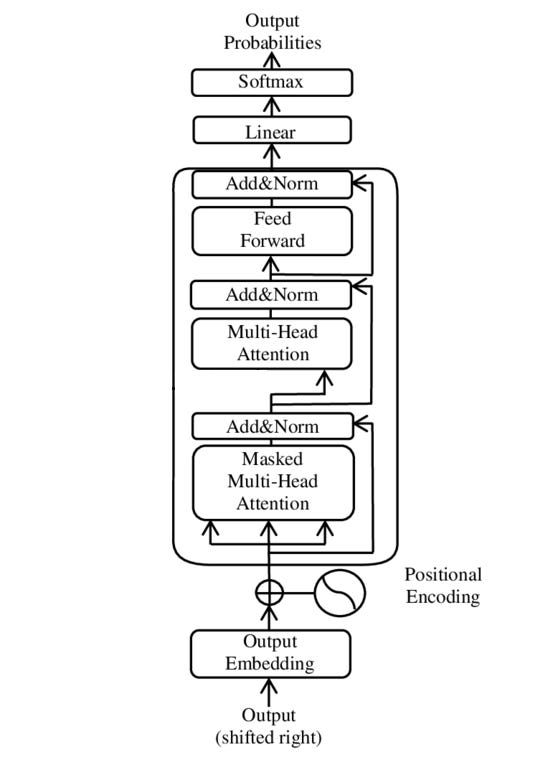
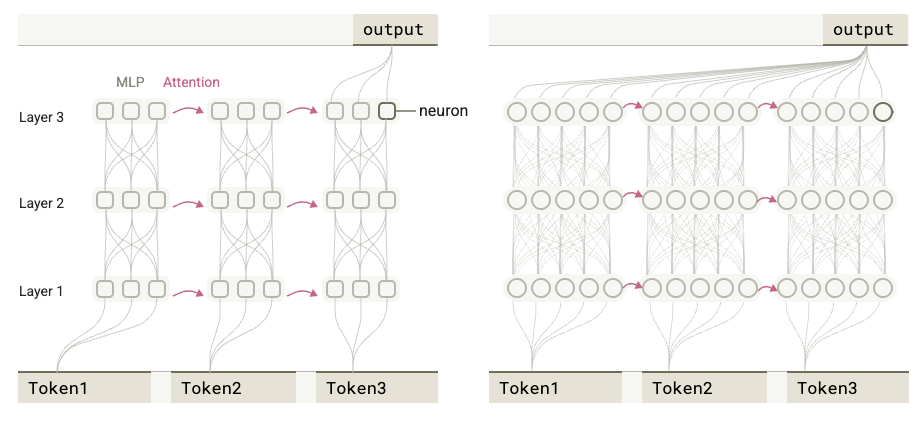
An immutable target: No writing or rewriting of target model weights occurs. This is in service of maintaining an authentic explanation. No specific architecture to the author’s knowledge has been made public on the target model, so we’ll substitute here the generic conceptual architecture of the decoder-only transformer which the target models are presumably based.
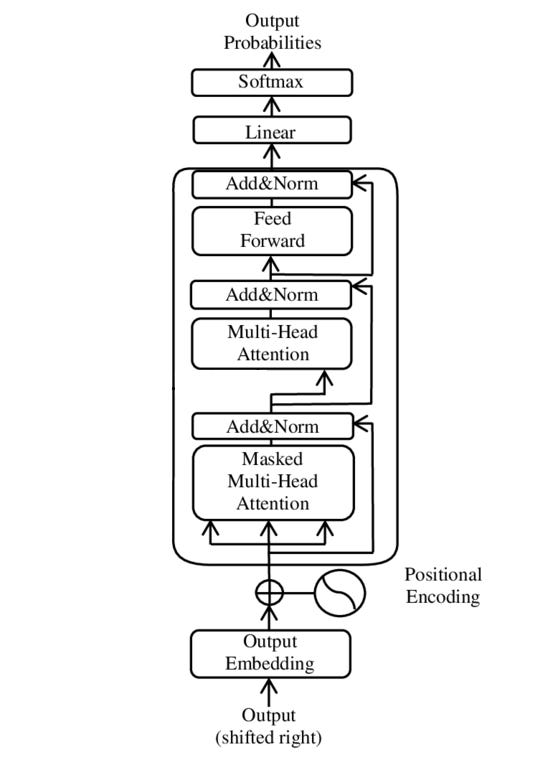
Notional decoder-only transformer architecture, only one transformer block shown. The Anthropic paper targets an 18-layer transformer model, Claude Haiku 3.5 is of unknown depth. Image credit: Wikipedia. Frozen attention heads: The transformer attention mechanism is applied naturally for a given input sequence, but is neither traced nor recomputed when interventions are done on the network for explainability. See here for discussion.
Freezing attention patterns is a standard approach which divides understanding transformers into two steps: understanding behavior given attention patterns, and understanding why the model attends to those positions. [1]
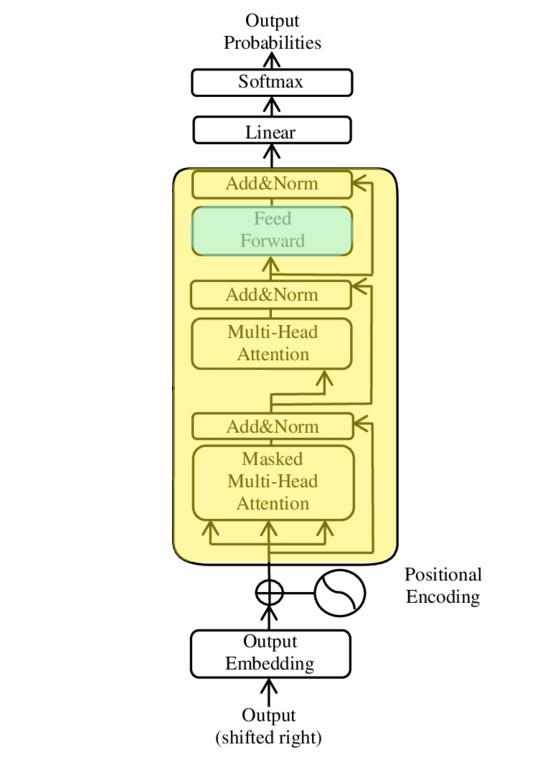
Hence the focus of the paper is on disentangling the relationships in the fully-connected portion of the transformer blocks (called out in green below). See Limitations below.
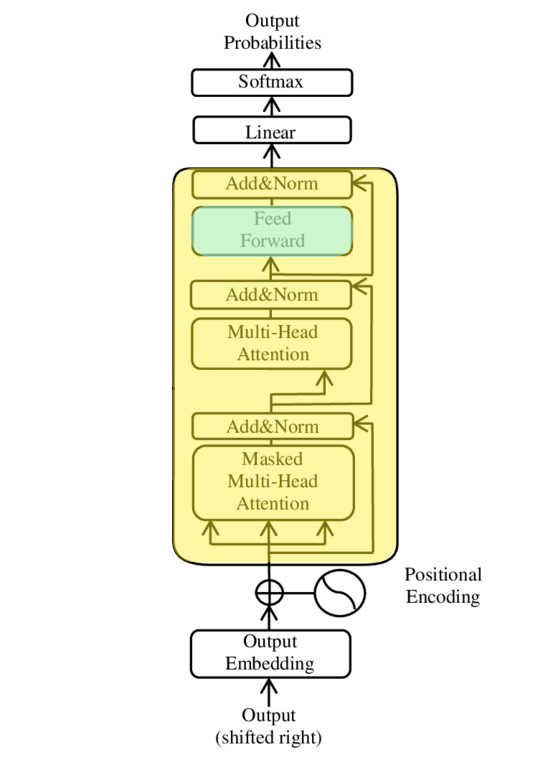
Activations in the transformer layers which are only computed once for a given sequence and then frozen for all interventions are shown in yellow. Activations which are recomputed, albeit in the transcoders (see below) are shown in green. Image credit: Wikipedia. The choice to freeze the attention mechanism places the explainability focus entirely to the dense connections within the fully-connected MLP layer.
Transcoders : The dense layers which are the subject of scrutiny in the paper are generally inscrutable due to polysemanticity. An antidote to this dense, entangled representation is a parallel, sparse, fully-connected network. The sparse representation is trained to mimic the MLP with an aim of achieving monosemanticity, and is thus significantly more vulnerable to human analysis and chaining during circuit tracing.
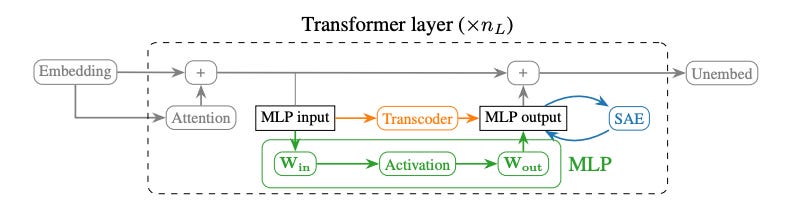
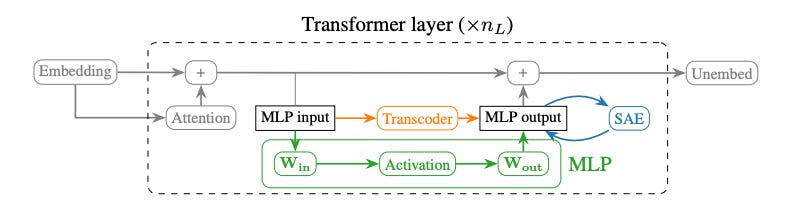
Figure 3. Role of the transcoder intervention in simulating dense layer behavior, which is notably different than the SAE approach (attempts only to explain a given layer’s activations). Reproduced under fair use for purposes of critical review. Source: Anthropic, “Towards Monosemanticity: Decomposing Language Models With Dictionary Learning” 2023 [8]. Cross-layer application of transcoders: The target of the interventions studies in the paper are again the MLP layer highlighted above and shown below in series. Each layer’s context is passed to the subsequent layer as shown. Note attention mechanisms are omitted in the image.
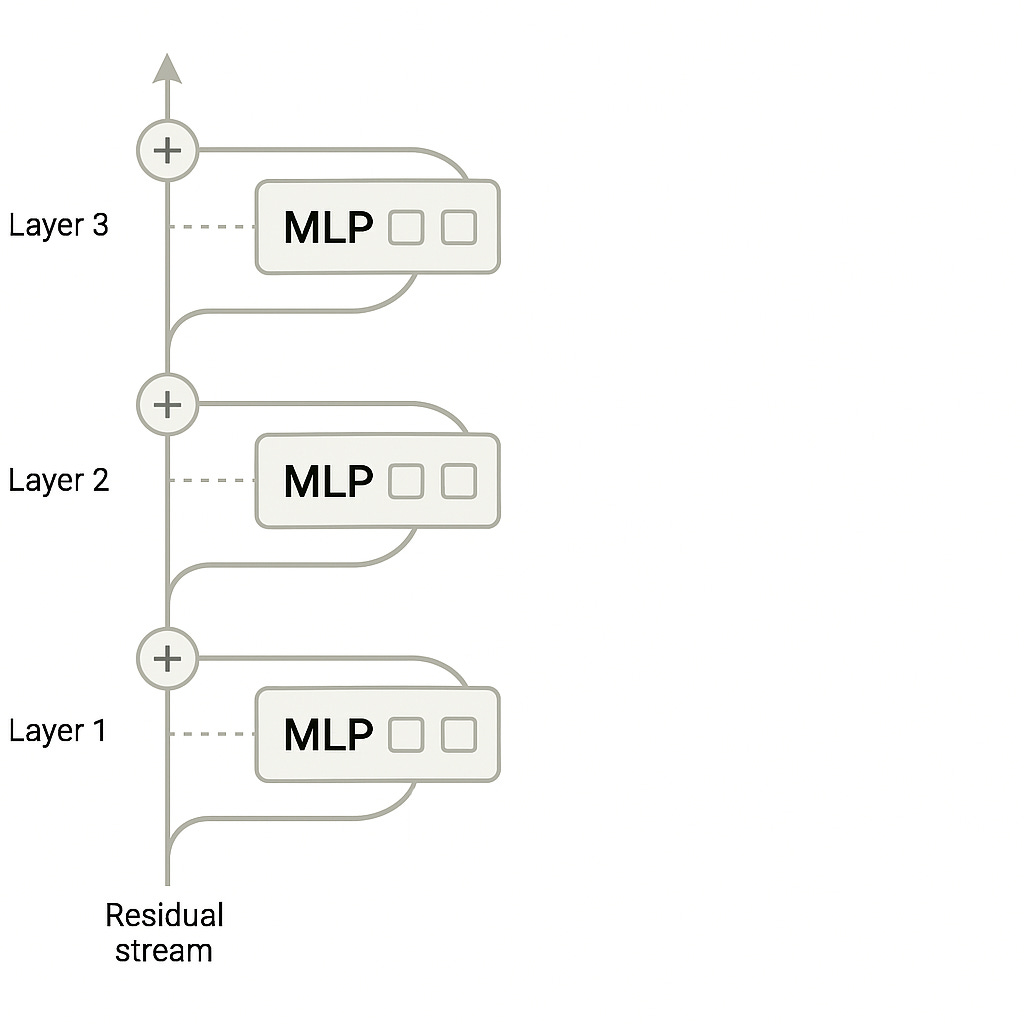
Target of the Anthropic intervention, the multi-layer perceptron within each layer of the model. Reproduced under fair use for purposes of critical review. Image source: Circuit Tracing paper [1] The inter-layer or cross-layer transcoder (CLT) receives the output of the prior MLP network and is trained to mimic the outputs of its sibling MLP, ultimately passing the resulting output to all subsequent CLTs.
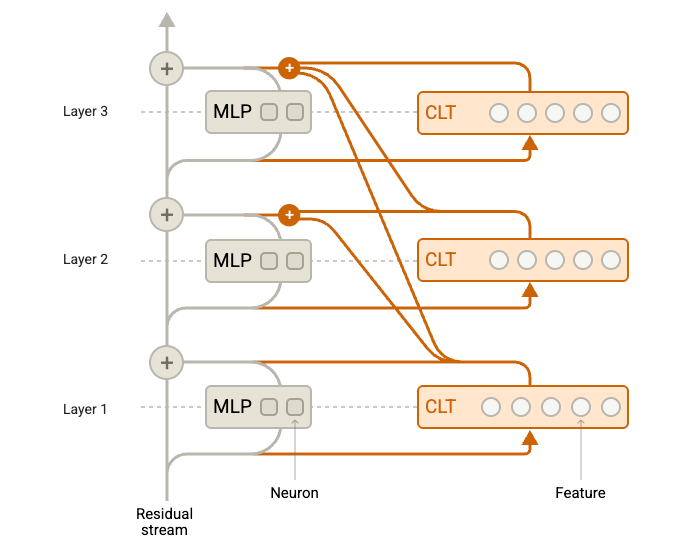
Model augmented with cross-layer transcoders that subsume the MLP functionality during circuit analysis [1]. Note that the CLT outputs are effectively skip connections providing their features to all subsequent transformer blocks. Reproduced under fair use for purposes of critical review. Image source: Circuit Tracing [1] Use of the CLTs as a replacement model: After training transcoders to approximate the behavior of their sibling MLPs, those transcoders can be swapped in during the forward pass. The resulting replacement network can then be harnessed to identify and track sparse features that map to more intuitive concepts.
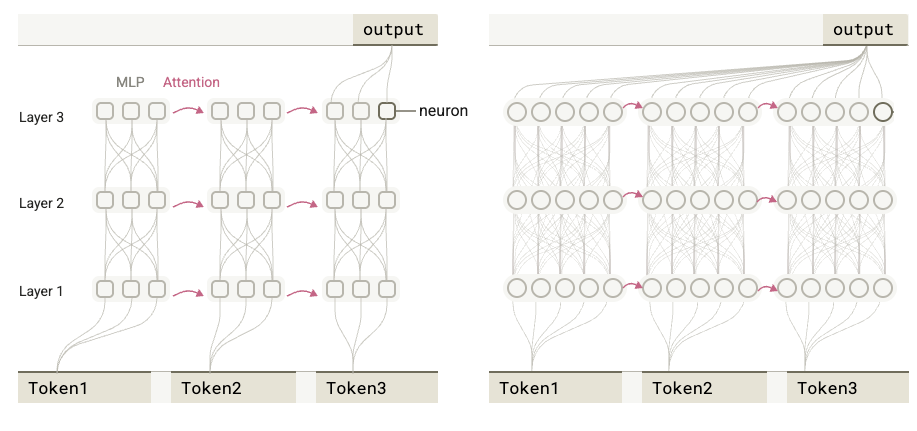
Dense MLP layers and sparse MLP layers. Notional unmodified forward pass of target network illustrated on the left. Forward pass under the sparse replacement model on the right. Reproduced under fair use for purposes of critical review. Image source: Circuit Tracing [1] Use of error nodes: The replacement model, which recruits the attention computations of the base model but substitutes the interpretable transcoders for the base model’s MLP layers, does not precisely reproduce the activations of the base model. This is undesirable as the compounding effect of minor errors changes the model output which we desire to fix for inspection. The authors use error nodes, which compensate for the minor differences in the transcoder layers and guarantee that the output of each replacement layer is identical to that of the base model for a given input.
In concert, the above provide functionally-equivalent layers that support isolating relationships within and across the model for a given input sequence.
Exploiting the Intervention
So far we have described the purpose for and nature of the decomposition of the network’s features in service of interpretability. We now look at the nature of the resulting inspection and tracing of interactions which is exhaustively covered in the paper [1] and its companion [2].
Attribution Graphs
The authors provide an accessible, interactive web interface for exploring precomputed and manually analyzed input sequences. The resulting attribution graphs trace the activations for a given prompt through the replacement network. Numerous examples of in-depth analysis can be found in the companion paper [2]. The interactive figures in the digital edition of the paper are a powerful tool for comprehending the research. The open-source Neuronpedia circuit-tracer furnishes a related, interactive tool that enables exploring these same circuits. Studying the replacement network feature interaction at a high-level allows the researchers to develop end-to-end explanations for model reasoning and are a critical aspect of the overall method validation strategy.
Pruning
The task of assigning concepts to features is a manual one. The authors undertake pruning to a) remove features that are not activating strongly or b) which are activating but are proven to not have an effect on the output they aim to explain. This was viewed as an essential step to reduce thousands of activations down to a reasonable number a human can make sense of, but it reduces the faithfulness of the reproduced circuit.
Features
As previously outlined, features encode concepts that can aid interpretability in isolation or in aggregate as part of a circuit. These features are most easily studied for a single input sequence, but can be studied across input sequences to better appreciate the semantics they bear. Interestingly the authors note that when features have small activations they often remain polysemantic, despite efforts to the contrary in the transcoder training setup. [1]
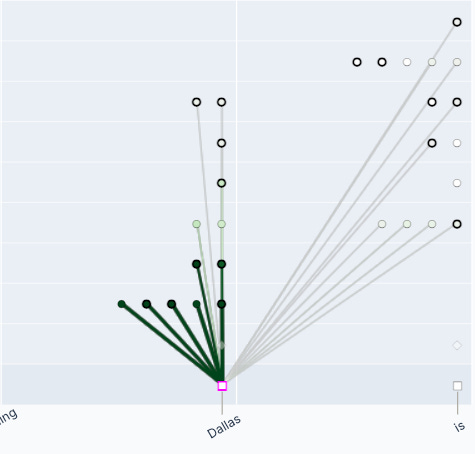
By analyzing feature activations across prompts, the Anthropic team can arrive at pithy descriptions for the feature’s role in model token predictions.
Supernodes
Aggregating neurons into features arrives at an intuitive atomic concept, but analyzing thousands of features that may be active in any given circuit risks depleting cognitive bandwidth of the analyst. Here the authors employ the concept of a supernode, which groups related features, often across layers, to represent a higher-level, interpretable concept. The below figure illustrates a recurring example used by the authors.
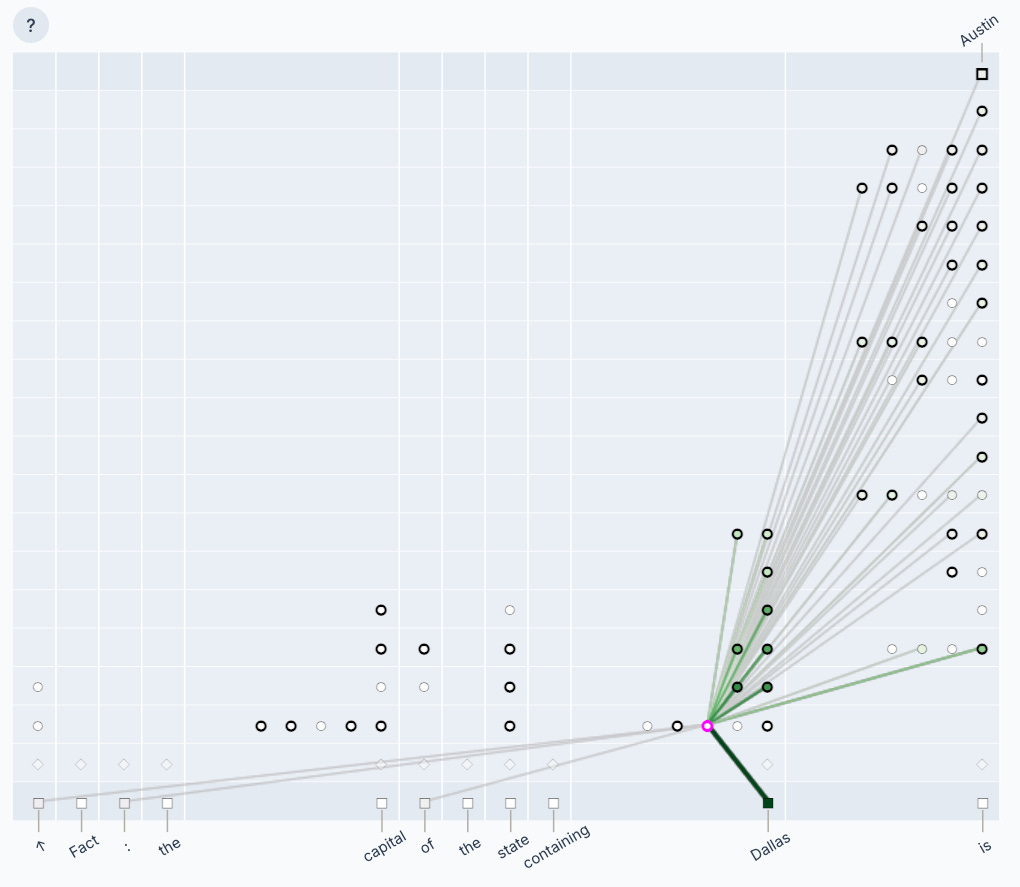
Aggregating features as a supernode also serves to simplify the articulation of more complex concepts in the resulting analysis. The below figure illustrates a cluster of supernodes for the same input prompt.
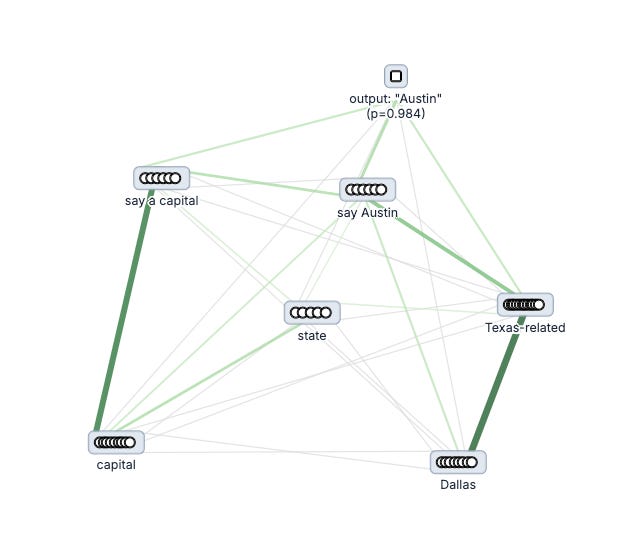
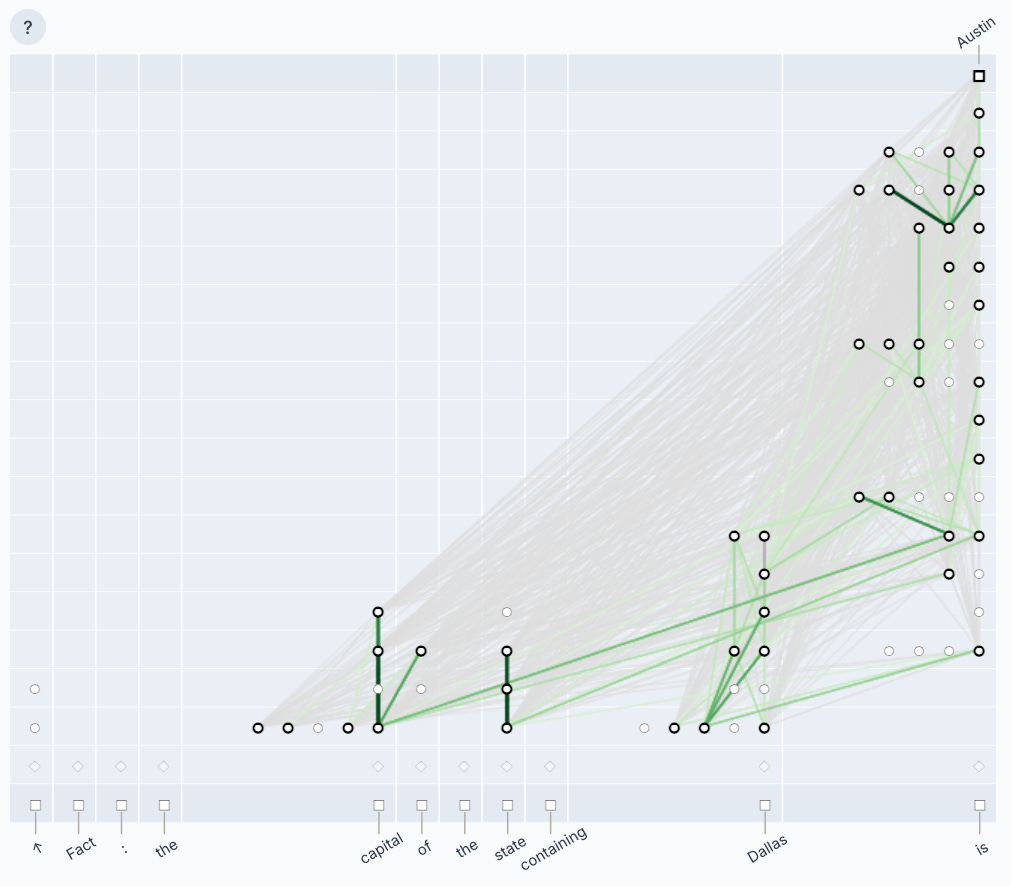
Validation
The process of validating hypotheses is critical to the impact and utility of the research. The authors inventory qualitative analysis that is performed and report quantitative measures that both engender confidence and suggest future research directions.
Features
Feature validation is implausible to conduct exhaustively, but the authors present thousands of feature visualizations in the companion paper [2] that help reinforce the utility and explanatory power of the outlined techniques. Below is an example feature that contributes to the model emitting a capital (of a jurisdiction).
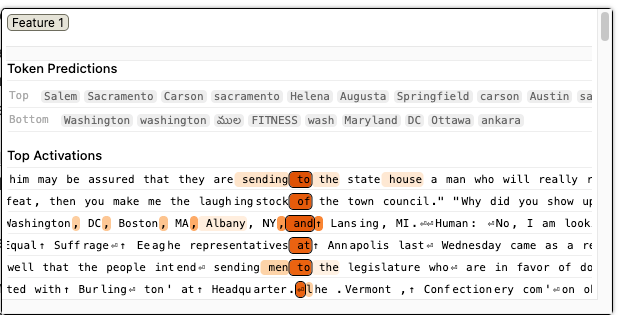
By repeated analysis and identification of atomic features, the Anthropic team provides an intuitive confirmation of interpretability and lay the groundwork for higher-level explainability constructs.
Transcoder Design
The authors attempt to quantify the impact of transcoder design on the reconstruction of features, reporting reductions in reconstruction error (of the MLP output the transcoder is designed to mimic) and feature sparsity as the transcoder size grew. In addition, the paper outlines a pair of techniques that aggregated LLM-based scoring to assess the over interpretability of named features identified in trained transcoders, and found that these scores increased alongside sparsity and reconstruction error. These conclusions impart some confidence that the transcoder is a suitable fit, with the size of the transcoder playing a central role in the overall explainability end-goal.
Perturbation
As outlined earlier, attribution graphs allow hypotheses to be put forward about what is motivating a given response (by inspecting the replacement network activations between input and output). This strategy risks an unfaithful albeit monosemantic relationship being constructed in the replacement network. How do we know that the replacement network is a soothsayer and not a storyteller? The authors are clear that interventions are imperative to validate their hypotheses. If we think a feature encoding the concept of a chicken exists and is a prerequisite to answering questions about poultry reliably, an intervention on this feature should create a commensurate change in the model's output.
The author’s interventions are designed to confirm or refute causality and are exclusively performed on the replacement network. The authors implement this with constrained patching, which proceeds as follows:
The base model is run and its outputs at each layer are recorded.
Features to be suppressed or amplified (see here for nuances on steering) for a target layer are perturbed at the input to the replacement layer.
The forward pass proceeds with the perturbed output of the replacement layer being provided only to downstream frozen MLP layers.
This technique allows isolation of effects and permits multiple interventions to be run simultaneously. The effect of repeated application of this strategy is a causal explanation for network behavior, which is what the entire value proposition of the research rests on.
In contrast with the purely qualitative evaluation criteria put forth for feature validation, the authors provide a few quantitative methods for assessing the utility of the attribution graph. Notably they investigate tradeoffs of the shorter circuit paths that CLTs enable (over per-layer transcoders), the prevalence of error nodes in circuits, and the impacts of pruning intensity. Their findings suggest some limitations and directions for further research.
Limitations and Critique
The authors inventory numerous shortcomings in their approach and set the scene for follow-on work. This section gives light treatment to some of the identified limitations and self-critique.
CLTs are able to generate shorter circuit lengths but they do so by introducing a series of skip connections that are controversial due to their absence in the transformer architecture. This improves the simplicity of the explanation (shorter circuit length, see path length discussions), but may do so at the expense of mechanistic faithfulness.
The methodology laid out in the paper acknowledges up front that freezing the attention heads in the transformer is a limitation, but one the authors and the larger mechanistic interpretability community seem to acknowledge as necessary given the scope of the challenge.
The sparse transcoders are orders of magnitude larger than the MLP layers they are designed to emulate. The 18L model was tested with 300K to 10M features while the Haiku model replacement network ranged from 300K to 30M features [1]. See also implementation details. The pronounced increase in the memory and compute required to train and deploy the replacement network limits the applicability of the technology.
Despite the efforts the research team has undertaken to make the overall system approachable, the analysis, labeling and circuit tracing tasks are daunting and not readily approached at scale or (yet) automated. See associated discussion.
Despite its size, the replacement network is not able to fully represent all of the superimposed states that the dense network maintains. The authors refer to the gap between their representation and the target networks as dark matter and the resulting error nodes they employ undermine confidence in the explainable circuits the current method produces.
While the CLT approach enables global model insights by studying the resulting replacement model weights and linkages, the authors report this network remains mostly inscrutable.
While the research resonates dramatically with our intuition, and satisfies to a degree our craving for understanding, the brittleness and limitations of the current state-of-the-art are evident.
Interpretation
The methodology outlined in the paper and copious examples of intuitive abstractions seem to have real explanatory power of the sort the mechanistic interpretability movement is after. This paper and the Anthropic literature on interpretability are striking for their emphasis on making their results approachable, without obvious sacrifice of rigor.
While causality can and is asserted by way of statistical verifications on the interactions of features, the incorporation of error nodes, the aggressive feature pruning and the potential for the replacement network to smuggle in polysemanticity are problematic. This gives one the feeling that the door is open for the replacement network to project a different logic than the frozen layers it was conceived to explain. Anthropic reports their test cases replacement network matched the original model’s output in 50 percent of test cases. This is cause for celebration, perhaps, but also for doubt.
We must not fall into the trap of believing we fully understand neural networks just because we believe we saw that neuron 349 in layer 7 is activated by daisies. [13]
It’s worth asking whether striving for human-centric interpretability in every circuit is even sustainable. Could we make use of an exhaustive inventory of internal circuits and their reason for existing even if coded in a grammar we implicitly understood? It seems plausible that as models increase in sophistication and complexity, we’ll be increasingly unable to contend (or desire to engage) with a full feature decomposition. Mechanistic interpretability may always be chasing a complete explanation for model behavior as complexity continues to increase.
Perhaps it will be enough to have a tool for introspection, even if a global appreciation is elusive. A microscope doesn’t give us the ability to fully appreciate the orientation and position of every atom in an object under study. Yet, the venerable microscope’s ability to reveal fine-grained detail nonetheless enables a host of thoughtful interventions. So too may mechanistic interpretability grant the power to surgically introspect and intervene on pathways that can lead to a safer, more aligned and more interpretable future.
Citations
Ameisen, et al., "Circuit Tracing: Revealing Computational Graphs in Language Models", Transformer Circuits, 2025. Retrieved from https://transformer-circuits.pub/2025/attribution-graphs/methods.html
Lindsey, et al., "On the Biology of a Large Language Model", Transformer Circuits, 2025. Retrieved from https://transformer-circuits.pub/2025/attribution-graphs/biology.html
Lin, J. (2023). Neuronpedia: Interactive reference and tooling for analyzing neural networks [Software]. Retrieved from https://www.neuronpedia.org
Rudin, C., Chen, C., Chen, Z., Huang, H., Semenova, L., & Zhong, C. (2022). Interpretable machine learning: Fundamental principles and 10 grand challenges. Statistic Surveys, 16, 1-85.
Chan, L. (2024, April 26). Superposition is not "just" neuron polysemanticity. AI Alignment Forum. Retrieved from https://www.alignmentforum.org/posts/8EyCQKuWo6swZpagS/superposition-is-not-just-neuron-polysemanticity
Nanda, N. (2024, July 7). An extremely opinionated annotated list of my favourite mechanistic interpretability papers v2. AI Alignment Forum. Retrieved from https://www.alignmentforum.org/posts/NfFST5Mio7BCAQHPA/an-extremely-opinionated-annotated-list-of-my-favourite
Olah, C., Bricken, T., Templeton, A., Jermyn, A., Henighan, T., & Batson, J. (2023, October 4). Decomposing language models with dictionary learning. Transformer Circuits. Retrieved from https://transformer-circuits.pub/2023/monosemantic-features/index.html
Dunefsky, J., Chlenski, P., & Nanda, N. (2024). Transcoders find interpretable LLM feature circuits. arXiv. Retrieved from https://doi.org/10.48550/arXiv.2406.11944
Nanda, N. (2022, December 21). A comprehensive mechanistic interpretability explainer & glossary. Retrieved from https://www.neelnanda.io/mechanistic-interpretability/glossary
Anthropic. (n.d.). Transformer circuits thread. Retrieved September 7, 2025, from Retrieved from https://transformer-circuits.pub/
Cammarata, et al., "Thread: Circuits", Distill, 2020. Retrieved from https://distill.pub/2020/circuits/
Olah, et al., "Zoom In: An Introduction to Circuits", Distill, 2020. Retrieved from https://distill.pub/2020/circuits/zoom-in/
Molnar, C. (2025). Interpretable Machine Learning: A Guide for Making Black Box Models Explainable (3rd ed.). christophm.github.io/interpretable-ml-book/
Zhang, Z., Lin, Y., Liu, Z., Li, P., Sun, M., & Zhou, J. (2021). Moefication: Transformer feed-forward layers are mixtures of experts. arXiv preprint arXiv:2110.01786.
Lindsey, J., Templeton, A., Marcus, J., Conerly, T., Batson, J., & Olah, C. (2024, October 25). Sparse crosscoders for cross-layer features and model diffing. Transformer Circuits. https://transformer-circuits.pub/2024/crosscoders/index.html
James, G., Witten, D., Hastie, T., Tibshirani, R., & Taylor, J. (2023). An introduction to statistical learning: With applications in Python. Springer. Retrieved from
https://www.statlearning.com/
Mienye, I. D., & Swart, T. G. (2024). A Comprehensive Review of Deep Learning: Architectures, Recent Advances, and Applications. Information, 15(12), 755. https://doi.org/10.3390/info15120755
Fair Use Disclaimer
This website may contain copyrighted material, the use of which has not always been specifically authorized by the copyright owner. I am making such material available in my effort to advance understanding of topics related to education and public discourse in the hopes of advancing the public good. I believe this constitutes a 'fair use' of any such copyrighted material as provided for in Section 107 of the U.S. Copyright Law.
If you wish to use copyrighted material from this site for purposes of your own that go beyond fair use, you must obtain permission from the copyright owner.
Within a given target model anyway